


Data Ecosystem
for your Organization
PRODUCTS • SERVICES
The Reveal framework is made of a set of modular services that allow cost-effective customization of the final solution. Each module is devoted to a specific task, ranging from the processing of the input documents to the semantic elaboration of texts to the implementation of retrieval functions. The final application is typically released as a Service Oriented Architecture that can be released on-premise, or in the Reveal’s cloud.

The Relation Extractor for big Organizations
When dealing with large-scale document collections, traditional Search Engines show their limit in supporting a wide range of complex queries.
For example, while an organization may be interested in knowing all the units performing a specific activity and all the other units that benefit from such activity, a search engine can only retrieve all documents mentioning the target office and the specific (maybe ambiguous) actions.
For big organizations it is crucial to adopt techniques for extracting knowledge automatically from texts, since most of the valuable information is only implicit (or hidden) within them.
A time-consuming activity to read such retrieved text is still required. On the other hand, this kind of queries can be easily accomplished by a database, but the information required to populate such a transactional system is only reported in unstructured and heterogeneous documents.
In these scenarios, it is crucial to adopt techniques for extracting knowledge automatically from texts, since most of the valuable information is only implicit (or hidden) within them. This extracted information can be used to improve access and management of knowledge hidden in large text corpora. Entities like persons, activities or organizations, form the most basic unit of information. Moreover, occurrences of entities in a sentence are often linked through well-defined relations; e.g., occurrences of a unit and activities in a sentence may be linked through relations such as unit-performs-activity.
The automatic extraction of domain-specific knowledge supports the creation of semantic metadata related to concepts relevant to the Organization’s domain (e.g. events, locations and persons) and activities.
This allows:
- The automatic tracking of activities
- Search about them in past archives
- Visualize the aggregated information in meaningful forms
- Navigate across such information ecosystems
- Target intelligent aggregation (knowledge) and analysis (decisions).
The Effective Combination with Revealer
RelExt is designed to be a plug&play component for any of the other Reveal’s or Customer’s engines. Can be included in an existing application as a standard library or invoked as a Service.
In input, it requires texts processed by RevNLT (the linguistic processor provided by Reveal) and extracts the set of discovered entities and relations. These can be used in the client workflow (e.g. populating knowledge graphs) or used in combination with Revealer, the Semantic Search Engine provided by Reveal. This combination is extremely effective as the output of RelExt can be used, for example, to augment the semantic metadata during the indexing and retrieval of documents.
As a result, the user can express queries such as:
“Search all sentences mentioning units that collaborate on some activity with an input unit”.
RelExt is entirely implemented in JAVA and can be included in an existing application as a standard library or invoked as a Service in any Service Oriented Architecture.
In the Reveal service ecosystem, RelExt typically embodies all services involved in the linguistic processing of texts in order to automatically extract entities and relations. Moreover, it provides services that enable the indexing and retrieval of such information.
All these processes as summarized in the colored blocks from the following picture:
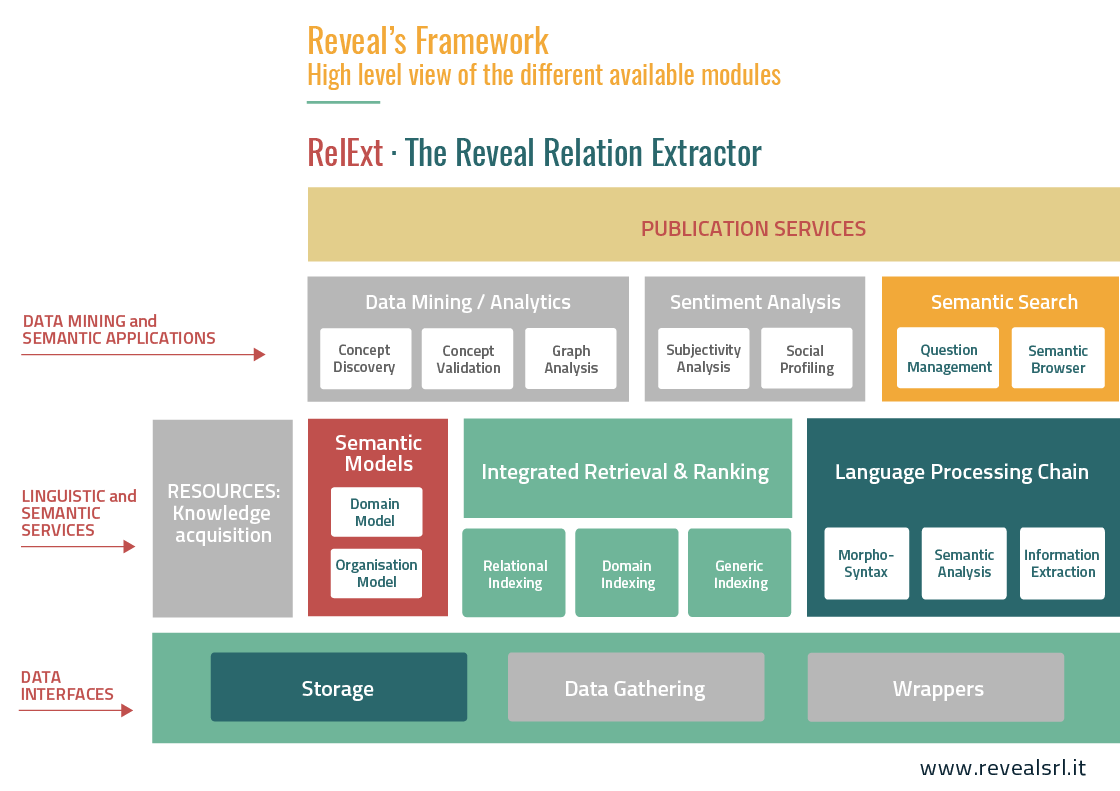
- Data interfaces: these services enable the storage of semantic knowledge extracted by the relation extractor.
- Data mining and semantic applications: the semantic search services support the final user to easily access the factual knowledge extracted by the relation extractor.
- Publication services: the publication services enable interaction with the final user, generally through Web-applications that can be customized according to the clients’ needs.
- Linguistic and Semantic services: these services implement the linguistic analysis and indexing of input texts together with the extracted semantic relations. Dedicated services are devoted to the management of the domain and organizational model underlying the relational representation.