


DNA · ML e NLP per le indagini
INDAGINE • OPEN SOURCE INTELLIGENCE • ALLERTA TEMPESTIVA
L’IA è importante per la governance delle società e i sistemi intelligenti (agenti) possono svolgere il ruolo di strumenti cruciali contro la criminalità. Il monitoraggio, il tracciamento e l’allerta sulle attività illegali richiedono dei sistemi che possano individuare automaticamente le prove acquisite dai documenti.
Questo permette il tracciamento automatico delle attività sospette, la ricerca su di loro negli archivi del passato, la visualizzazione delle informazioni aggregate in forme intelligenti e la navigazione attraverso tale ecosistema di informazioni per indirizzare l’aggregazione intelligente (conoscenza) e l’analisi (decisioni).
Obiettivo tecnologico: Analisi dei documenti guidata dal Machine Learning e ricerca semantica nel dominio dell’investigazione
Utente di riferimento: DNA – Ministero degli Affari Interni
Timeline del Progetto: dal 2014
Processo di recupero delle informazioni
Il monitoraggio, il tracciamento e l’allerta sulle attività illegali richiedono dei sistemi che siano in grado di scoprire automaticamente le prove raccolte dai documenti.
L’estrazione automatica di informazioni specifiche del dominio favorisce la creazione di metadati semantici relativi ai concetti per gli argomenti di indagine (ad esempio eventi, luoghi e persone) e attività. Questo permette il tracciamento automatico delle attività sospette, la ricerca su di loro negli archivi del passato, la visualizzazione delle informazioni aggregate in forme significanti e la navigazione attraverso tale ecosistema di informazioni, per indirizzare l’aggregazione intelligente (conoscenza) e l’analisi (decisioni).
Tecniche di elaborazione del linguaggio naturale aumentate da algoritmi di Machine e Deep Neural Learning.
Trovare le informazioni di interesse all’interno del dominio di investigazione corrisponde a un processo di Information Retrieval (o IR), che dipende da strumenti di ricerca semantica verso le informazioni rese disponibili in modo implicito o esplicito nei documenti. Questo abbina le tecniche di Natural Language Processing incrementate con paradigmi di Machine e Deep Learning.
Reveal Estrattore delle relazioni (RelExt)
In questo progetto, tale conoscenza viene estratta e filtrata utilizzando il Reveal Relation Extractor (RelExt): esso elabora i testi di input al fine di identificare le entità di interesse per gli analisti, insieme alle relazioni esistenti tra loro.
Il sistema RelExt implica approcci di Machine Learning per l’elaborazione dei testi, basati su metodi neurali come Support Vector Machine e/o Deep Learning. Poiché questo tipo di entità e relazioni di interesse nel dominio di riferimento può cambiare nei diversi domini, un team di analisti ha identificato le citazioni di entità e relazioni di interesse all’interno dei documenti del cliente.
L’etichettatura di meno di un centinaio di testi permette di sviluppare un sistema capace di “leggere” una raccolta di diverse migliaia di documenti.
Questo materiale è stato poi utilizzato per ottenere automaticamente i modelli neurali, utili ad automatizzare l’elaborazione semantica dei documenti intercettati dal sistema, e per definire dei benchmark, utili per la misurazione quantitativa della qualità semantica dei processori. L’etichettatura di meno di un centinaio di testi permette di sviluppare un sistema che è in grado di “leggere” una raccolta composta da diverse migliaia di documenti. Di conseguenza, diverse centinaia di migliaia di menzioni a delle entità e relazioni sono state estratte automaticamente e utilizzate per popolare un database e un motore di ricerca semantico. Infine, questi ultimi possono essere consultati attraverso linguaggi di interrogazione standard, come SQL o SPARQL. Per questo motivo è possibile implementare in modo semplice un potente software di navigazione e analisi, come le schede grafiche, utili per navigare in questa enorme quantità di informazioni.
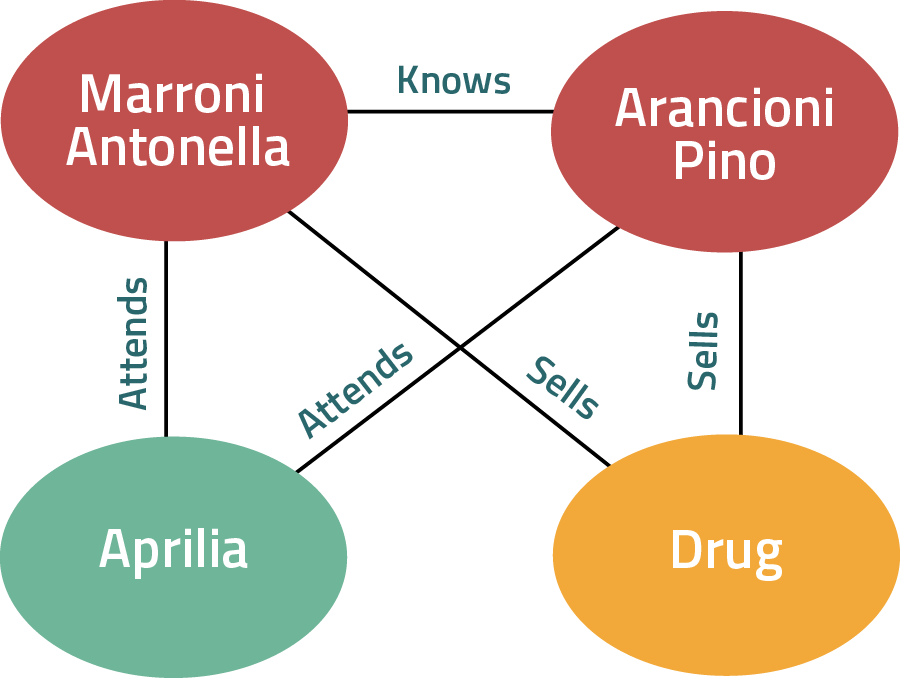
Re4act, il browser di Reveal per il tracciamento dei crimini
Questa Base di dati e il Motore di Ricerca Semantico possono essere infine consultati attraverso linguaggi d’interrogazione standard, come SQL o SPARQL. Questo permette la semplice introduzione di un potente strumento di navigazione e di analisi.
La navigazione è disponibile attraverso i diagrammi grafici, utili per navigare in questa enorme quantità di informazioni. Nel seguente diagramma (a sinistra) una moltitudine di individui (che si conoscono l’un con l’altro) può essere vista a colpo d’occhio insieme al luogo che hanno frequentato o al gruppo criminale al quale appartengono. Inoltre, è possibile consultare i paragrafi specifici dove queste entità sono menzionate in coerenza con il grafico (al centro) o il documento specifico che può essere letto dall’analista (a destra) dove tutte le entità scoperte sono esplicite (a destra in basso).
