


DNA · ML and NLP for Investigation
INVESTIGATION • OPEN SOURCE INTELLIGENCE • EARLY WARNING
AI is important for the governance of communities and intelligent systems (agents) can play the role of crucial tools against crime. Monitoring, tracking and alerting about illegal activities require systems able to automatically discover collect evidence from documents.
This allows the automatic tracking of suspected activities, search about them in past archives, visualize the aggregated information in meaningful forms and navigate across such information ecosystem to target intelligent aggregation (knowledge) and analysis (decisions).
Information Retrieval process
Monitoring, tracking and alerting about illegal activities require systems able to automatically discover collect evidence from documents.
The automatic extraction of domain-specific information supports the creation of semantic metadata related to concepts to investigation topics (e.g. events, locations and persons) and activities. This allows the automatic tracking of suspected activities, search about them in past archives, visualize the aggregated information in GGmeaningful forms and navigate across such information ecosystem to target intelligent aggregation (knowledge) and analysis (decisions).
Natural Language Processing techniques augmented with paradigms of Machine and Deep Learning.
Finding information of interest within the investigation domain corresponds to an Information Retrieval (or IR) process that depends on Semantic Search tools toward the information made available implicitly or explicitly by documents. This combines Natural Language Processing techniques augmented with paradigms of Machine and Deep Learning.
Reveal Relation Extractor (RelExt)
In this project, such knowledge is extracted and distilled using the Reveal Relation Extractor (RelExt): it processes input texts in order to identify entities of interest to analysts together with the relationships existing among them.
The RelExt system implements Machine Learning approaches for text processing, based on neural methods such as Support Vector Machine and/or Deep Learning. Since the type of entities and relations of interest in the target domain may change across the different domains, a team of analysts identified mentions to entities and relationships of interest within the client’s documents.
The labelling of less than one hundred texts allow to deploy a system able to “read” a document collection of several thousand documents.
This material was then used to automatically derive the neural models useful to automate the semantic processing of documents internalized by the system and to define benchmarks useful for the quantitative measurement of the semantic quality of the processors. The labeling of fewer than one hundred texts allows to deployment of a system able to “read” a document collection of several thousand documents. As a consequence, several hundreds of thousands of mentions to entities and relations were automatically extracted and used to populate a Database and a Semantic Search Engine. These can be finally queried through standard query languages, such as SQL or SPARQL. This enables the straightforward implementation of powerful navigation and analysis software, such as graphical dashboards, useful to navigate in this huge amount of knowledge.
Re4act, the Reveal Crime Tracking Browser
These databases and a Semantic Search Engine can be finally queried through standard query languages, such as SQL or SPARQL. This enables the straightforward implementation of powerful navigation and analysis software.
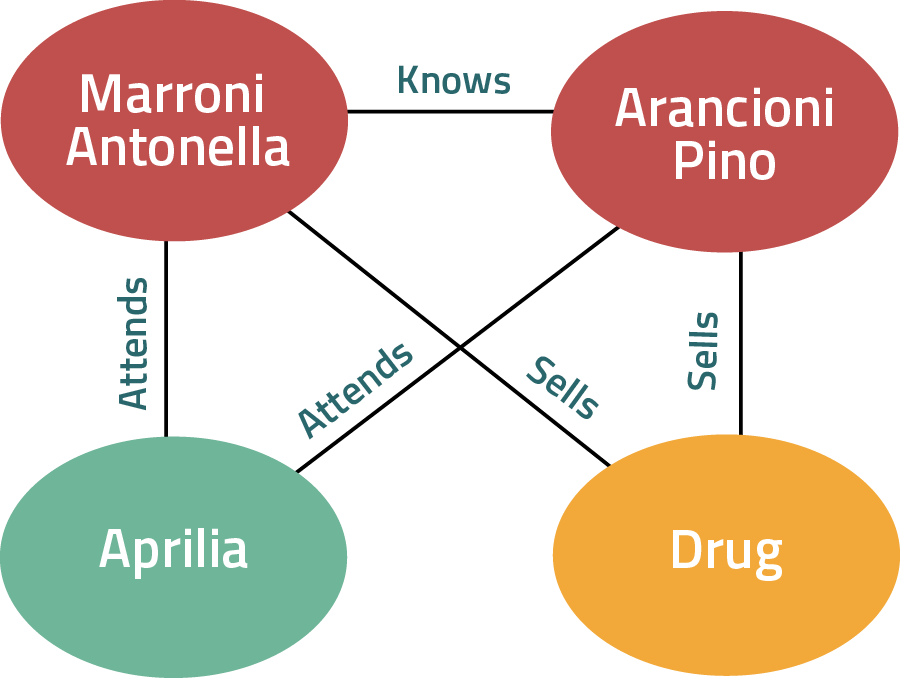
Navigation is available as graphical dashboards, useful to navigate in this huge amount of knowledge. In the following dashboard (on the left) a community of individuals (each knowing each other) can be seen at a glance together with the place they attended or the criminal group they belong to. Moreover, it is possible to browse the specific paragraphs where these entities are mentioned consistently with the graph (in the center) or the specific document to be read from the analyst (on the right) where all discovered entities are also made explicit (on the right in the bottom).
