


Lessons learned in Hi-Tech Major Subsea Supplier
ARTIFICIAL INTELLIGENCE · ENGINEERING
We supported one of the Major Norwegian companies, leader in the design and production of complex engineering systems in support of the subsea oil industry:
Reveal developed and delivered the first application of Semantic Technologies for the (semi)-automation of the Requirement Analysis phase within the subsea oil production industry.
Semantic Search and Conceptual Navigation for the Oil & Gas Industry
We supported one of the Major Hi-Tech Subsea Suppliers in Norway, a company leader in the design and production of complex engineering systems in support of the subsea oil industry. This field is particularly sensitive to cost and scheduled overruns.
The size and costs of the large-scale projects in which the supported company is involved (e.g. the release of new plants under the North Sea to pump oil from the sea bottoms) are the primary concern of the complex requirement engineering practices needed to optimize them.
Correspondingly, large-scale document management processes are operational over complex texts related to International Calls, Tenders as well as System Design and Requirement documents produced by the engineering teams.
The cost and schedule overruns are the major risks in these stages, and they have often their root cause in overlooked requirements and forgotten past lessons.
The Subsea Oil extraction industry is particularly sensitive to these losses due to the short project award and execution times that do not allow the complete compilation of a requirement database from the contract documents and appendixes. Specifically, product non-conformities to the intended use have required extensive rework to guarantee that expensive products are fit-for-purpose.
Semi-automation of the Requirement Analysis phase
Reveal developed and delivered the first application of Semantic Technologies for the (semi)-automation of the Requirement Analysis phase within the subsea oil production industry.
In this project, we demonstrated in the specific domain the effectiveness of Natural Language Processing and Machine Learning techniques in automatizing the semantic annotation and management of the involved documents.
By locating sentences expressing requirements and assigning them specific (ontological) types the project enabled extremely effective support to the design engineer in making available and quickly retrievable the whole body of relevant lessons learned.
Given the adoption of www standards, these types are widely reusable across future projects and scenarios.
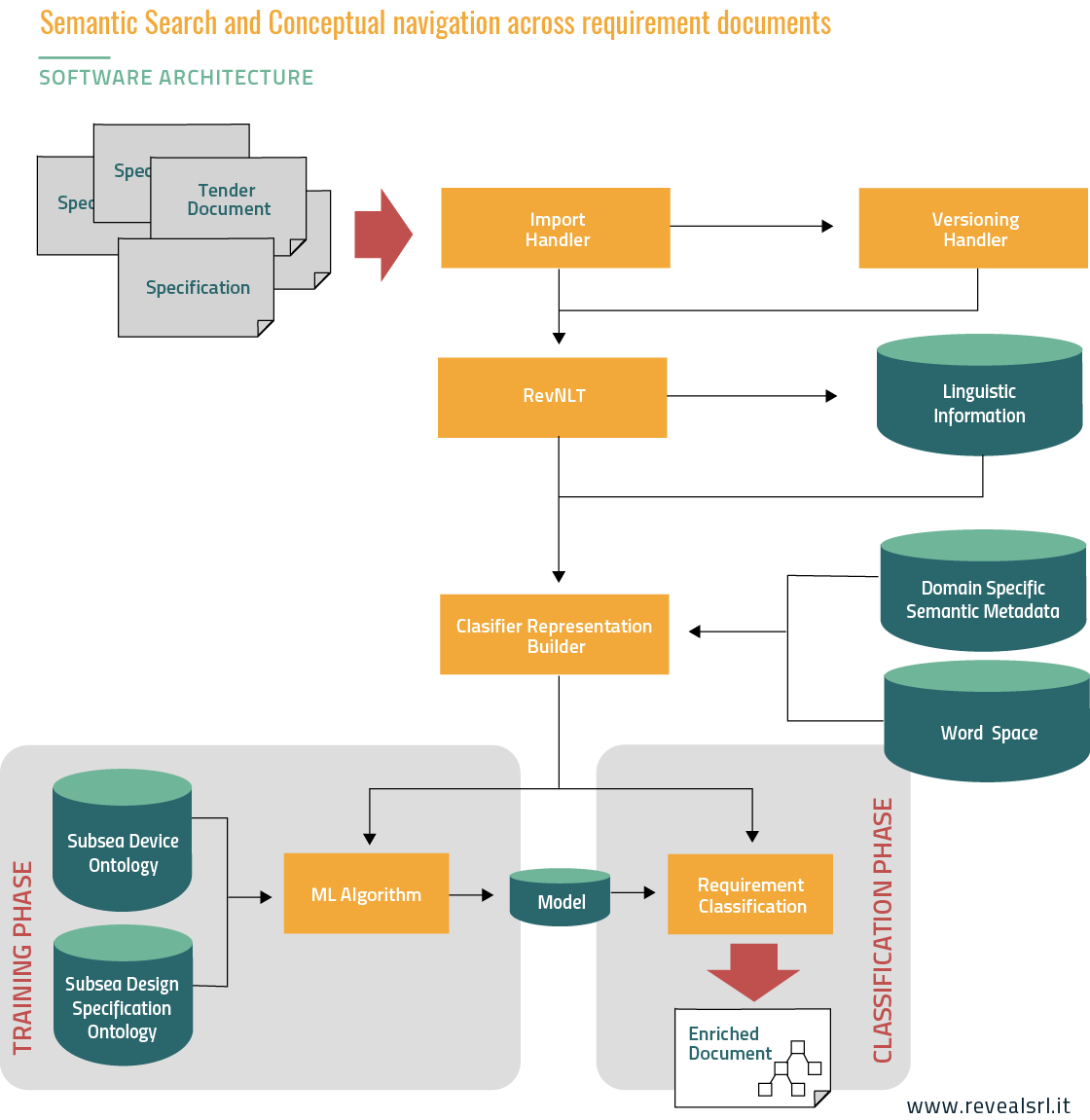
THE ARCHITECTURE:
Is shown in order to emphasize the different involved modules.
- The Import Handler loads and pre-processes the requirement documents, in order to acquire a representation that is readable by the following modules.
- The Versioning Handler realizes the functionalities to handle the documentation versioning. When the upgrade of a given document is available, it retrieves differences between the documents in order to enable the tracking of the requirements across upgrades. As an example, when a sentence expressing a requirement is added, the system will assign a proper type to the new sentence, and it will thus notify the addition of a novel requirement.
- The Reveal Natural Language Toolkit (RevNLT) implements techniques of natural language processing (NLP) in order to achieve a morphosyntactic analysis of the nature of the texts contained within documents. An example of this analysis is the segmentation of the documents into sentences, the identification of the main classes that characterize grammatically the words that make up the sentences (e.g. nouns, verbs or adjectives); the parsing of sentences, which allows the extraction of linguistic constructs as the Subject-Verb-Object Complement. In the overall architecture, this system represents a module providing linguistic information useful to build artificial representation for the learning algorithm.
- The Classifier Representation Builder acquires each sentence, selects from the NLP system the proper information needed to generate the artificial representation useful for the learning algorithm. Some information can be derived by lexicon and terminology collection that represents Domain-Specific Semantic Metadata. The lexical generalization acquired through the Word Space model
- The Conceptual Browser exploits linguistic and ontological information (e.g. lessons learned types as “Manufacturing” or “Quality Control”) to support navigation and exploration across similar lessons. The resulting browser allows to retrieve newer lessons (nodes in dark green in the figure below), estimate their relevance as a function of the corresponding text semantics and, correspondingly, visualize them closer to (or further) the originating query (light green nodes in the figure), in agreement with higher (or lower) relevance scores.
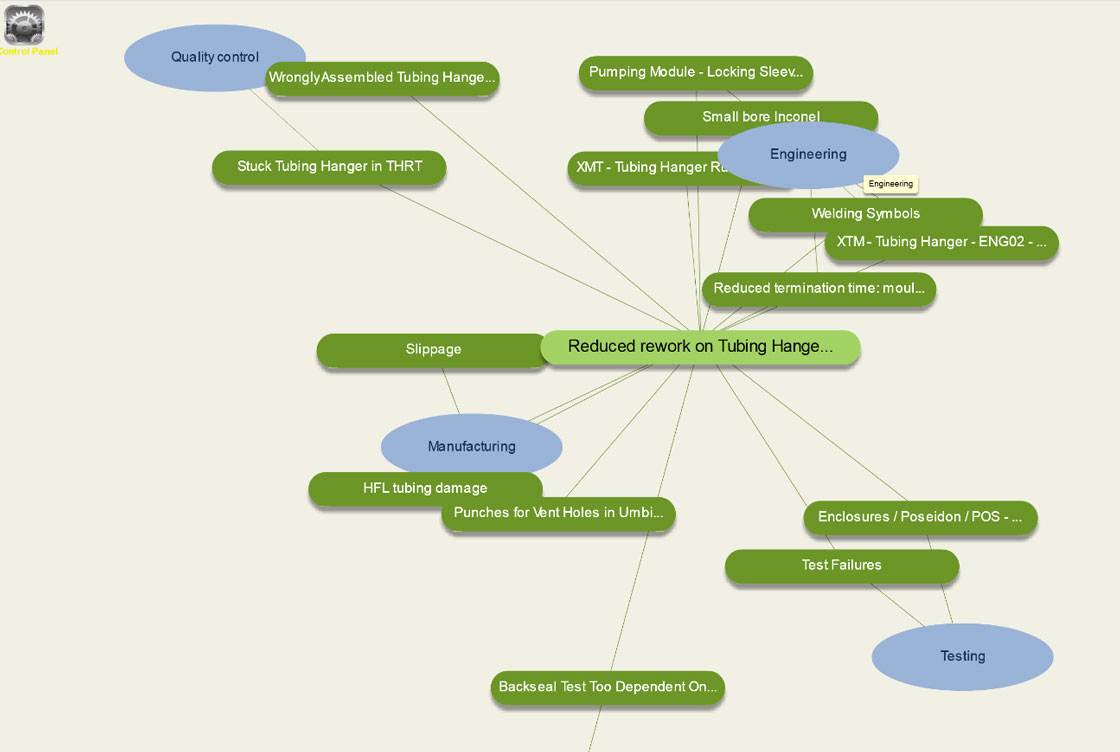
The Semantic Search Engine
A Semantic Search engine has been implemented customizing the Revealer Search Engine to exploit the ontological information derived by the Semantic Processing carried out in this project.
TASK:
- Retrieve documents (as well as passages or sentences) from the company’s document collection that refer to specific concepts;
- Enable a Semantic Filter of the retrieved material (e.g. selecting only sentences related to the Analysis of the “Design Pressure” of an “XMT”);
- Enable Advanced Reports from the retrieved material (e.g. clustering results of a Search Engine by considering the specific requirements involved in the retrieved texts)
The development of the user interface has been carried out taking into account the following guidelines:
- Expressivity: The User Interface must expose all information extracted from the text.
– Differences between sentences
– Discovered entities (Standards, Components and Physical quantities) - Navigability: The UI must allow users to navigate within the results provided by the system being always able to recover the set of concepts discovered by the system.
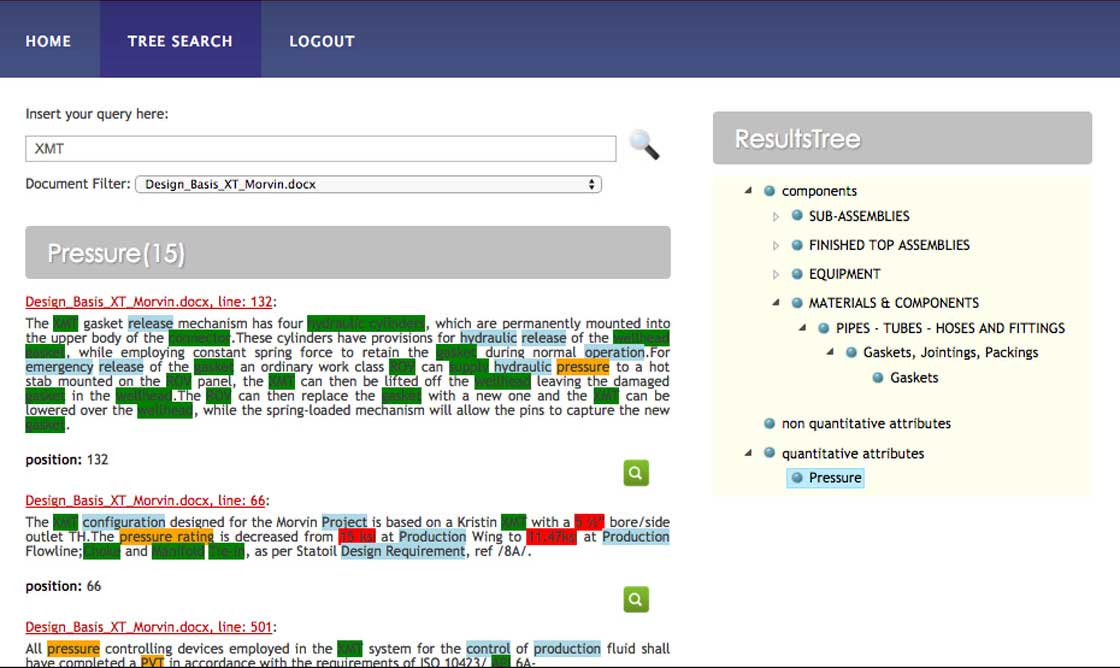
Above, a screenshot of a subset System results for the query “XMT” when the “Pressure” concept is selected, with classified and color-coded information. The color-coding allows the user to quickly focus on the type of requirement the specification is dictating.
The “soft” requirements are notoriously difficult to identify and fully chart
The system enables the engineer to quickly discriminate between “hard” quantitative requirements (i.e. numeric values of performance such as pressure, temperature, speed, etc.) and the harder to identify “soft” or “modal” requirements, which stipulate the intended mode of operation, maintenance, man-machine interaction. The “soft” requirements are notoriously difficult to identify and fully chart, the system assists the design team by providing the data in a form conducive to codification in action or interface registers.