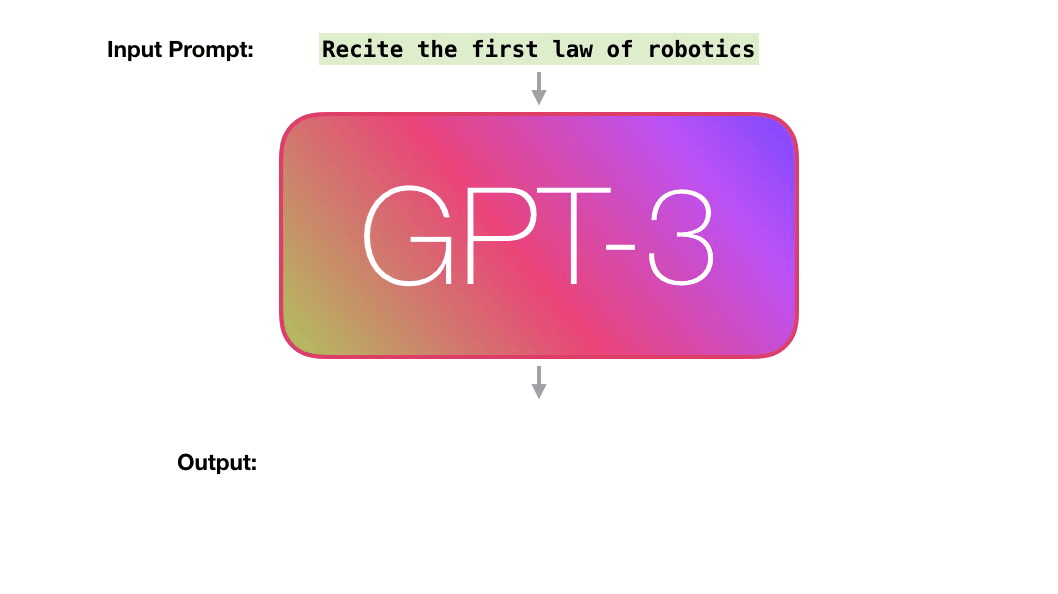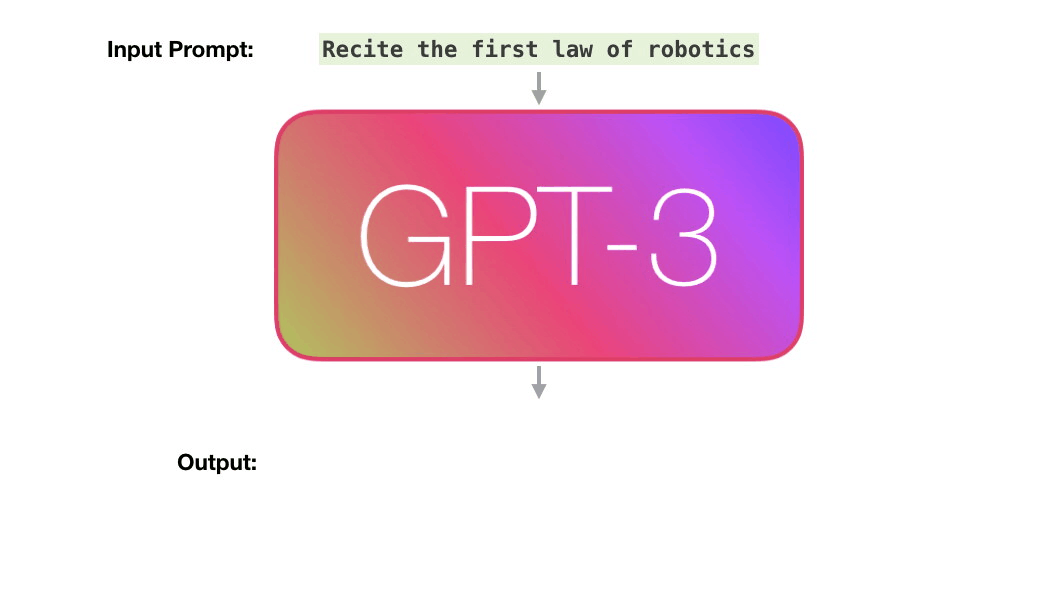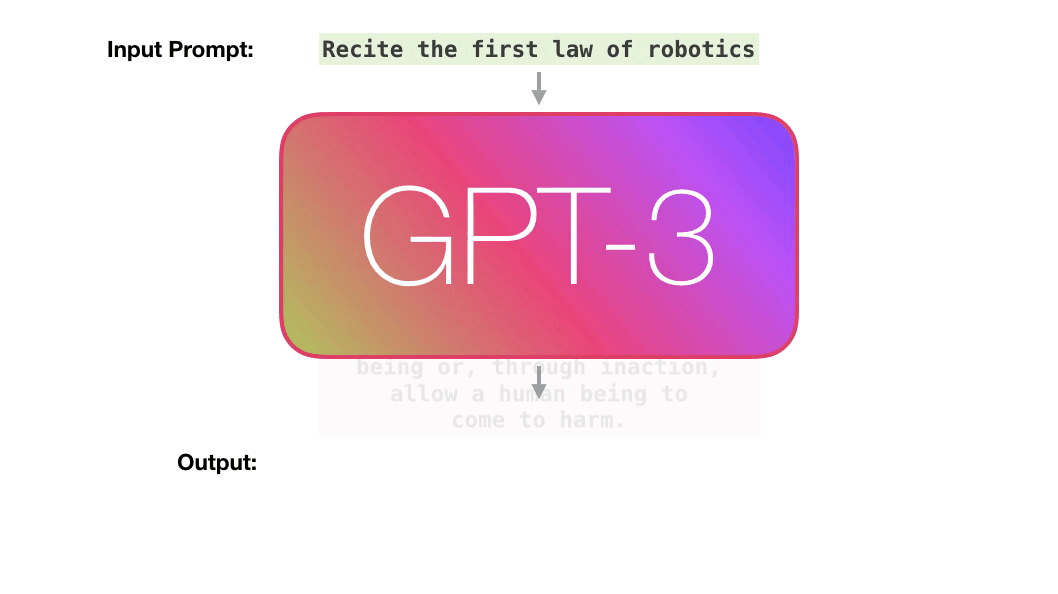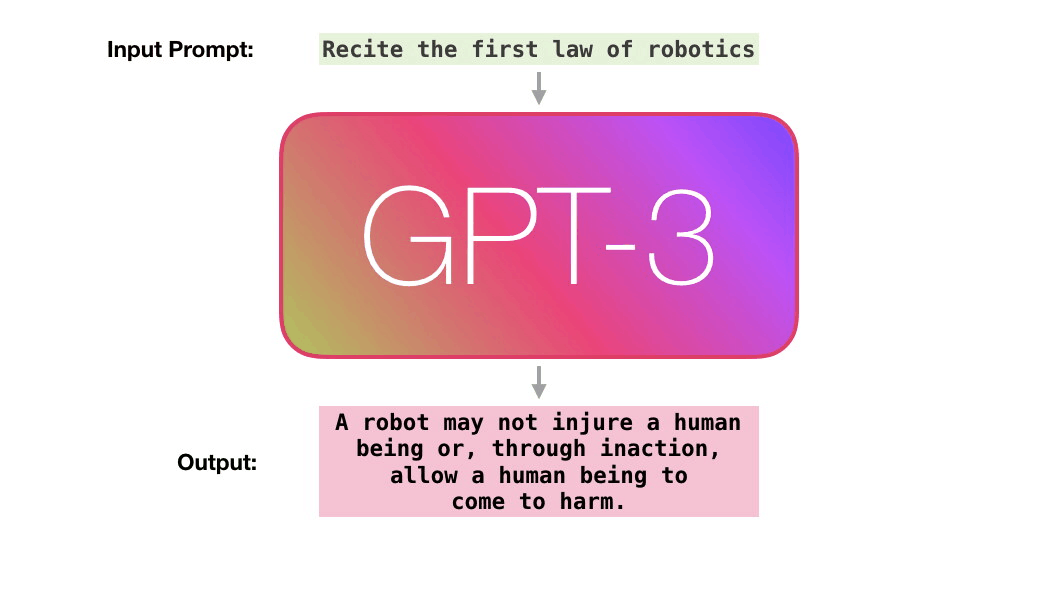
Gli attuali modelli neurali, come GPT-3, stanno superando sfide sino a pochi anni inaccessibili: risolvere problemi complessi di inferenza testuale con un metodo unificato di apprendimento neurale, cioè i trasformatori.
Tali paradigmi si basano sulla nozione centrale di modello del linguaggio, qualcosa che può essere addestrato a prevedere un compito semplice (come la sostituzione coerente delle parole in un testo), ma che è poi in grado di codificare la conoscenza linguistica implicita nelle frasi coerenti di una lingua, le argomentazioni convincenti ed i fatti del mondo reale. Il risultato è che possono essere facilmente riutilizzati come base per altri compiti a grana più fine, come la traduzione in un’altra lingua o la capacità di rispondere alle domande, interessati da un addestramento specifico, generalmente chiamato “fine tuning”.
Se la domanda è: GPT-3 è già un esempio rappresentativo di una forma generale di IA, anche senza fine tuning, allora “No” è probabilmente la risposta.
La capacità di applicare algoritmi di apprendimento del linguaggio non supervisionato su larga scala non deve essere confusa con lo streaming analytics di altri tipi. L’idea di base è che mentre i flussi di dati numerici (ad esempio, quelli generati dai sensori), quelli cioè a cui la fisica tradizionalmente si rivolge, possono essere utilizzati per fornire modelli predittivi accurati dei fenomeni misurati da tali dati, il linguaggio naturale è pervasivo in aree della conoscenza umana molto diverse tra loro. L’apprendimento guidato dal testo può essere percepito come una forma specifica di apprendimento (ad esempio, basato sul paradigma dei “trasformers” come in GPT-3) ma riguarda fenomeni universali. Il processo di apprendimento qui produce modelli che forniscono un resoconto generale degli elementi di conoscenza, principi e regole generali di utilizzo della conoscenza espressa dalle lingue, elementi molto più cruciali per ciò che chiediamo all’IA generale.
Se la domanda è: GPT-3 è già un esempio rappresentativo di una forma generale di IA, anche senza fine-tuning, allora “No” è probabilmente la risposta. Tuttavia, le critiche all’approccio sono di solito troppo aggressive, in quanto tendono a concentrarsi su specifici aspetti deboli dei modelli attuali, che vengono enfatizzati eccessivamente.
Come al solito, la verità sta in qualche modo nel mezzo. Si noti che i modelli simili a GPT-3 si basano fortemente su un meccanismo di apprendimento semplice, ma NON sono macchine semplici. Ogni approccio di questo tipo ha una forte struttura imposta dalla distinzione tra pre-addestramento e fine-tuning, dai vincoli basati sull’attenzione e dalla definizione specifica di diversi compiti specifici come le inferenze testuali di qualche tipo, compiti che sono in grado di innescare correttamente il fine-tuning. È quindi certo vero che l’apprendimento automatico, e tutti i suoi successi, non costituisce un meccanismo magico universalmente appropriato, ma dimostra sempre più fortemente una forte base rappresentazionale (cioè cognitiva). Le macchine GPT-3 continuano tale tradizione, e anche se sono ancora sulla strada dell’IA generale, possiamo guardare a loro come ispirazione per approssimazioni sempre migliori dell’intelligenza umana.