


Ecosistema di Dati per la vostra organizzazione
PRODOTTI • SERVIZI
Il framework di Reveal è costituito da un insieme di servizi modulari che consentono una personalizzazione della soluzione finale, economicamente vantaggiosa. Ogni modulo è dedicato ad un compito specifico, che va dall’elaborazione dei documenti di input, all’elaborazione semantica dei testi fino all’implementazione delle funzioni di retrieval. L’applicazione finale è tipicamente rilasciata come Architettura Orientata a Servizi che può essere rilasciata on premise, o nel cloud di Reveal.

Il Motore di Ricerca Semantica
Revealer è un motore di ricerca semantica che permette di recuperare ciò che si cerca nella propria collezione di documenti, senza conoscere le parole usate nei testi per descriverlo.
Modelli statistici e ontologici permettono di trovare le informazioni in base al loro significato e di pubblicare i risultati attraverso report o grafi semantici, utili per una più efficace comprensione della risposta. Revealer è un’architettura distribuita a servizi, che si integra facilmente con gli altri servizi Reveal, come l’elaboratore linguistico RevNLT, per indicizzare e recuperare i documenti grazie ad una profonda comprensione del loro contenuto.
Gli utenti possono interagire con Revealer NON solo utilizzando semplici termini di interrogazione come nei motori di ricerca tradizionali. Interi documenti o paragrafi possono essere utilizzati come query.
Revealer è potenziato dai sottosistemi di estrazione e classificazione delle informazioni per analizzare i documenti e arricchirli con metadati semantici e rappresentazioni neurali che riflettono il loro contenuto.
Revealer agisce come un assistente che legge i vostri testi e assegna ad ogni documento, paragrafo o frase una serie di “tag semantici” che riflettono il loro significato e consentono funzionalità di ricerca potenti e intuitive. Queste, per essere efficaci, devono essere semplici e immediate: gli utenti possono interagire con Revealer non solo utilizzando semplici termini di interrogazione come nei motori di ricerca tradizionali. Gli elaboratori di query combinano NLP e Machine Learning per supportare l’implementazione di sistemi di Question Answering, per recuperare testi specifici contenenti le risposte alle domande dell’utente. Inoltre, specifici motori di Similarità Semantica permettono di recuperare unità di informazione, superando l’intuitiva ma limitativa ricerca di termini, in favore della ricerca di documenti simili: intere unità di informazione (documenti o paragrafi) possono essere utilizzate come query.
Inoltre, i documenti possono essere organizzati e recuperati automaticamente secondo modelli ontologici forniti dall’Organizzazione, sempre con metodi di Machine Learning. Permette di supportare navigazioni espressive attraverso i documenti recuperati, come ad esempio i grafi semantici.
Altamente modulare e scalabile per ridurre i costi
Si tratta di un’Architettura Orientata ai Servizi che può essere utilizzata direttamente dagli utenti finali attraverso web-app specifiche o da altre applicazioni, esponendo servizi web standard.
Revealer e tutti i suoi componenti sono interamente scritti in JAVA, inclusi i classificatori e i moduli di elaborazione del linguaggio. Supporta sistemi di indicizzazione su larga scala, robusti ed efficienti (come SOLR) e può essere facilmente installato in qualsiasi ambiente con costi contenuti. È estremamente modulare in modo da fornire, efficacemente, una soluzione personalizzata all’utente finale. Nell’ecosistema dei servizi di Reveal, Revealer racchiude tipicamente tutti i servizi coinvolti in un processo di Ricerca Semantica, come riassunto nei blocchi colorati dell’immagine seguente:
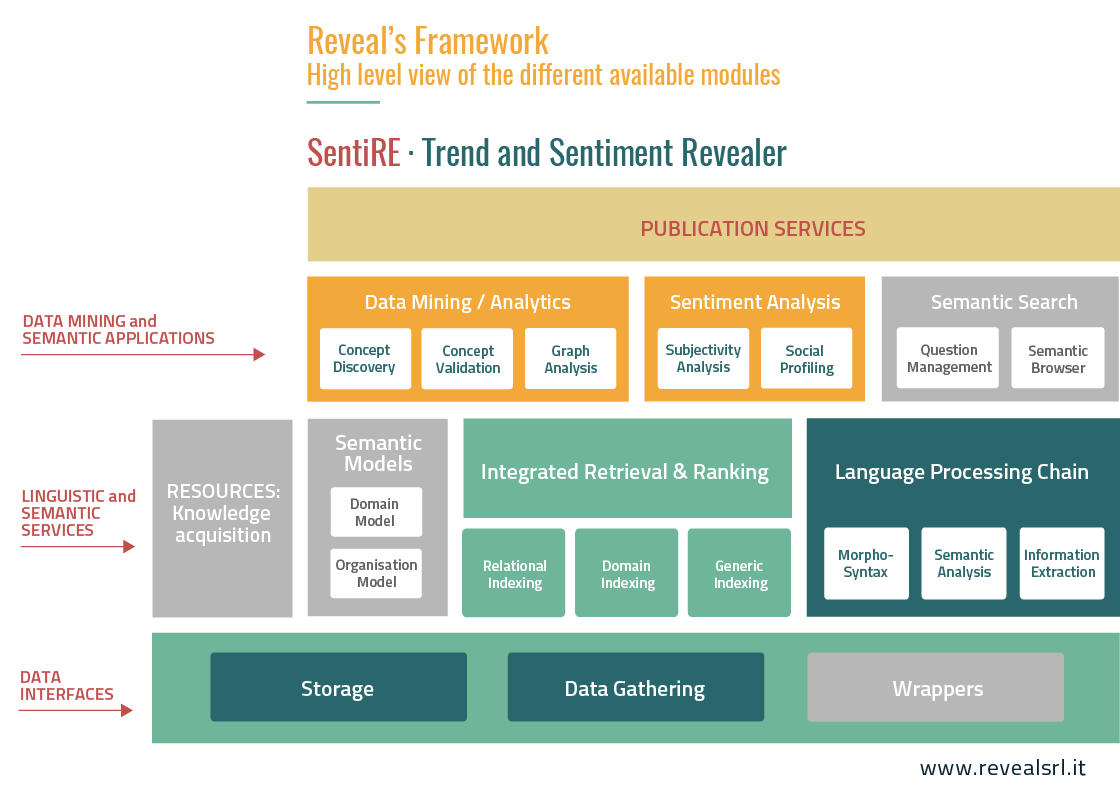
- Interfacce dati: implementano i wrapper per collezioni di documenti in ingresso e permettono di memorizzare gli indici semantici in appositi data-lakes.
- Servizi linguistici e semantici: implementano l’analisi linguistica dei documenti di input, la memorizzazione e la manipolazione dei modelli organizzativi e l’indicizzazione del materiale di input.
- Data mining e applicazioni semantiche: i servizi di data mining permettono di elaborare l’intera raccolta di documenti per localizzare e sintetizzare automaticamente le concettualizzazioni utili ad arricchire i documenti di input con i metadati che riflettono il loro contenuto. I moduli di ricerca semantica permettono la comprensione profonda delle query dell’utente e consentono una navigazione semantica guidata della raccolta di documenti (ad esempio, attraverso i grafi semantici).
- Servizi di pubblicazione: i servizi di pubblicazione consentono l’interazione con l’utente finale, generalmente attraverso applicazioni web che possono essere personalizzate in base alle esigenze del cliente.